 Sam Stoelinga
Sam Stoelinga
Elastic Data Processing on OpenStack with Spark, Tachyon and Swift
Mon 09 November 2015 | Last updated on Tue 06 December 2022This post will describe how to configure, build and deploy Spark with Tachyon and Swift as storage. This architecture is meant to be more suitable for running Big Data workloads on top of the cloud such as OpenStack.
Using Swift as storage layer for Spark gives us the ability to utilize the cloud paradigm with Big Data. We can now on demand spin up n-amount of VMs, run a spark job with input data from Swift, then when finished store the result back in Swift and finally when the job is finished, destroy the VMs. This kind of elastic data processing, using Tachyon for fast localized in-memory storage gives you high performance and also elasticity of the cloud.
The general architecture looks like this:
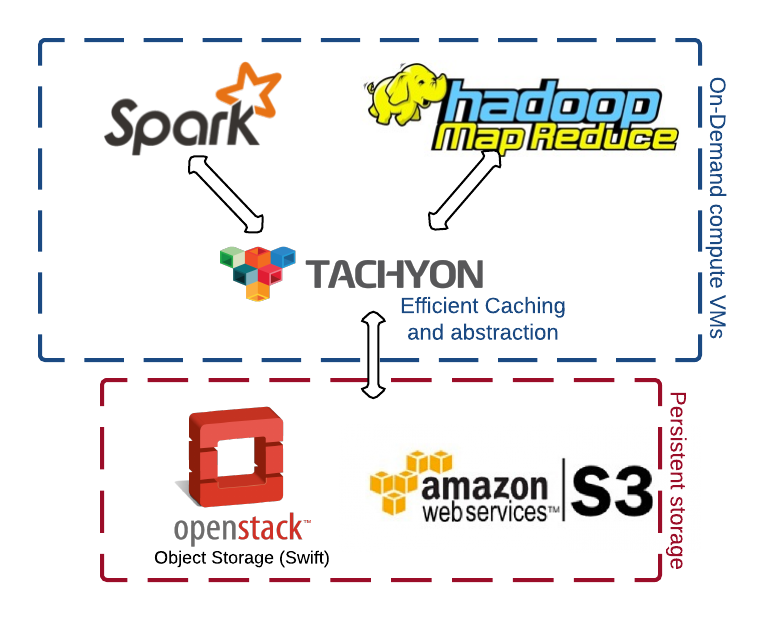
Assumptions:
- You have a working Mesos cluster that can run Spark jobs
- We have two nodes: mesos-master-1 (192.168.111.54) and mesos-slave-1 (192.168.111.57). We will run tachyon master on the mesos-master-1 node and tachyon worker on mesos-slave-1
- OpenStack Keystone and Swift are available at 10.10.10.10
- Tachyon 0.8.0 is deployed and configured to use Swift as underfs
The general workflow of this post is:
- Installation of Tachyon 0.8.0 with Swift as underFS on the mesos-slaves
- Building Spark 1.6.0-SNAPSHOT from latest master branch with Tachyon 0.8.0 and tachyon-underfs-swift as dependencies.
- Running an example Spark job which uses Tachyon for input and output.
Tachyon 0.8.0 installation with Swift as underFS
Download and extract Tachyon to the mesos-master and mesos-slave
wget http://tachyon-project.org/downloads/files/0.8.0/tachyon-0.8.0-hadoop2.6-bin.tar.gz
scp tachyon-0.8.0-hadoop2.6-bin.tar.gz mesos-master-1:/srv/
scp tachyon-0.8.0-hadoop2.6-bin.tar.gz mesos-slave-1:/srv/
ssh mesos-master-1 "cd /srv/ && tar xzf tachyon-0.8.0-hadoop2.6-bin.tar.gz"
ssh mesos-slave-1 "cd /srv/ && tar xzf tachyon-0.8.0-hadoop2.6-bin.tar.gz"
On both mesos-master-1 and mesos-slave-1, copy /srv/tachyon-0.8.0/conf/tachyon-env.sh.swift to /srv/tachyon-0.8.0/conf/tachyon-env.sh
mv /srv/tachyon-0.8.0/conf/tachyon-env.sh{.swift,}
Make minor modifications to /srv/tachyon-0.8.0/conf/tachyon-env.sh on both mesos-master-1 and mesos-slave-1:
export TACHYON_MASTER_ADDRESS=192.168.111.54
export TACHYON_UNDERFS_ADDRESS=swift://spark.swift1
The TACHYON_MASTER_ADDRESS is set to the use the external IP of the mesos-master node. The variable TACHYON_UNDERFS_ADDRESS is set to swift://spark.swift1 where spark is the name of the Swift container and swift1 is an arbitary name to specify an Swift connection object defined in tachyon/conf/core-site.xml.
Now in core-site.xml we need to define how to connect to Swift. This is done by changing settings for swift1 provider in core-site.xml. I'm using Keystone to authenticate with Swift and also to retreive the correct endpoint.
I've changed core-site.xml according to my Swift environment and copied it to tachyon/conf/core-site.xml. The following changes were made:
<property>
<name>fs.swift.service.swift1.location-aware</name>
<value>false</value>
</property>
<property>
<name>fs.swift.service.swift1.auth.url</name>
<value>http://10.10.10.10:5000/v2.0/tokens</value>
</property>
<property>
<name>fs.swift.service.swift1.http.port</name>
<value>8080</value>
</property>
<property>
<name>fs.swift.service.swift1.region</name>
<value>RegionOne</value>
</property>
<property>
<name>fs.swift.service.swift1.public</name>
<value>true</value>
</property>
<property>
<name>fs.swift.service.swift1.auth.endpoint.prefix</name>
<value>endpoints</value>
</property>
<property>
<name>fs.swift.service.swift1.tenant</name>
<value>spark</value>
</property>
<property>
<name>fs.swift.service.swift1.password</name>
<value>test123</value>
</property>
<property>
<name>fs.swift.service.swift1.username</name>
<value>spark</value>
</property>
After all config changes are done we can start launching the Tachyon master process on the mesos-master-1 node.
/srv/tachyon-0.8.0/bin/tachyon-start.sh master -f
After successful start of the tachyon master, also start the tachyon worker on mesos-slave-1:
/srv/tachyon-0.8.0/bin/tachyon-start.sh worker SudoMount
You should now have Tachyon running and you can access it via http://192.168.111.54:19999
Building Spark with Tachyon 0.8.0 and Swift
Checkout latest master branch of spark:
git clone https://github.com/apache/spark.git
Apply the following patches to core/pom.xml and make_distribution.sh to use tachyon 0.8.0 and to include hdfs as underfs dependency. Make sure to exclude mockito-all else the build will fail with
diff --git a/core/pom.xml b/core/pom.xml
index 570a25c..98285a0 100644
--- a/core/pom.xml
+++ b/core/pom.xml
@@ -262,7 +262,7 @@
<dependency>
<groupId>org.tachyonproject</groupId>
<artifactId>tachyon-client</artifactId>
- <version>0.8.1</version>
+ <version>0.8.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.hadoop</groupId>
@@ -287,6 +287,17 @@
</exclusions>
</dependency>
<dependency>
+ <groupId>org.tachyonproject</groupId>
+ <artifactId>tachyon-underfs-swift</artifactId>
+ <version>0.8.0</version>
+ <exclusions>
+ <exclusion>
+ <groupId>org.mockito</groupId>
+ <artifactId>mockito-all</artifactId>
+ </exclusion>
+ </exclusions>
+ </dependency>
+ <dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<exclusions>
diff --git a/make-distribution.sh b/make-distribution.sh
index e1c2afd..f676678 100755
--- a/make-distribution.sh
+++ b/make-distribution.sh
@@ -33,7 +33,7 @@ SPARK_HOME="$(cd "`dirname "$0"`"; pwd)"
DISTDIR="$SPARK_HOME/dist"
SPARK_TACHYON=false
-TACHYON_VERSION="0.8.1"
+TACHYON_VERSION="0.8.0"
TACHYON_TGZ="tachyon-${TACHYON_VERSION}-bin.tar.gz"
TACHYON_URL="http://tachyon-project.org/downloads/files/${TACHYON_VERSION}/${TACHYON_TGZ}"
Build Spark with Tachyon and Swift as underfs:
./make-distribution.sh --name spark-master-tachyon-0.8.0 --tgz --with-tachyon -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0 -DskipTests
Add core-site.xml which we used in Tachyon to the Spark tarball.
tar xzf spark-1.6.0-SNAPSHOT-bin-spark-master-tachyon-0.8.0.tgz
cp /srv/tachyon-0.8.0/conf/core-site.xml spark-1.6.0*/conf/core-site.xml
tar czf spark-1.6.0.tar.gz spark-1.6.0-SNAPSHOT-bin-spark-master-tachyon-0.8.0
For some reason Spark also needs core-site.xml with the Swift connection settings even though we already configured this in Tachyon.
Running a Spark job with Tachyon as input backed by Swift
Assuming that in our Swift container we have an object called output.log we can now create a Spark shell session and use
spark-shell
val textFile = sc.textFile("tachyon://mesos-master-1:19998/output.log")
textFile.count()
I've also verified that I could successfuly use sequenceFiles and Spark pickleFiles on Tachyon with Swift by running the Python spark jobs of my other project: Spark Computer vision